Modelos avanzados en evaluación de recursos pesqueros: Día 1
Sistema pesquero
¿Para qué nos sirven los modelos de evaluación?

Conceptos básicos
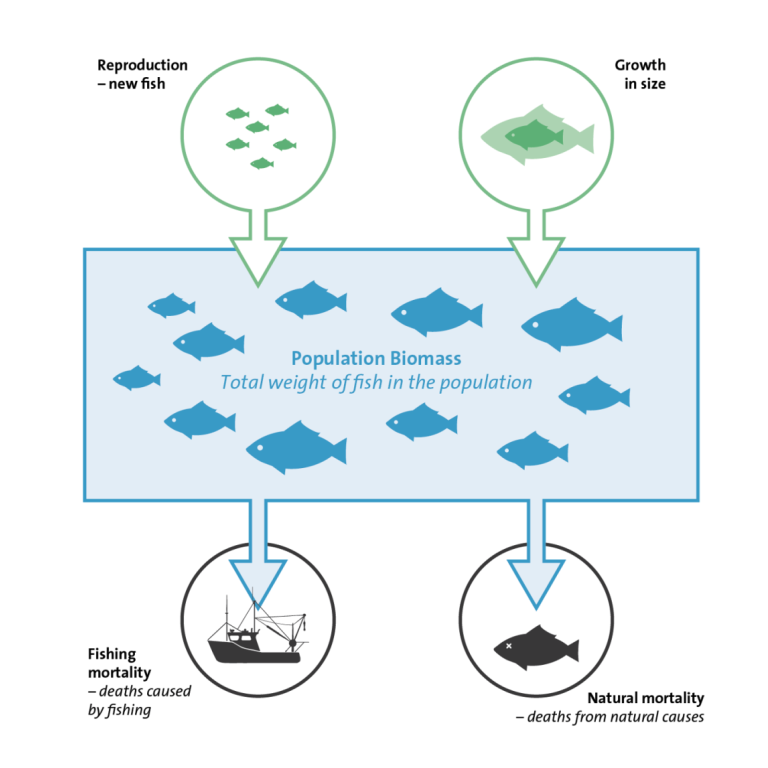
Stockholm University Baltic Sea Centre
Conceptos básicos
Diferencias claves en enfoques para estudiar poblaciones:
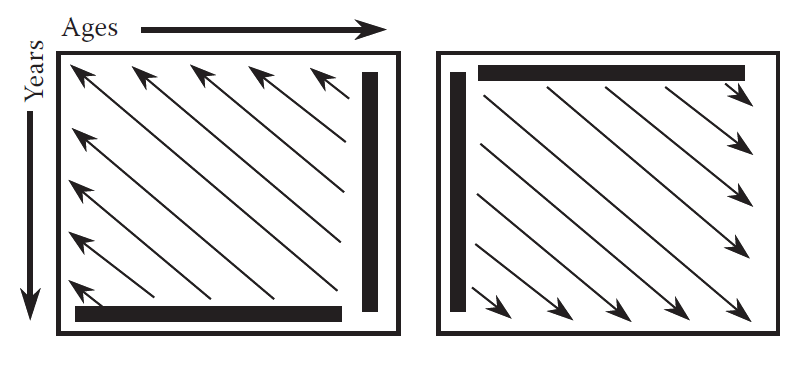
Haddon (2011)
Enfoque integrado

Haddon (2011)
Modelos state-space
- \(z_{t}\): estado en tiempo \(t\) (e.g., abundancia de la población)
- \(y_{t}\): observaciones
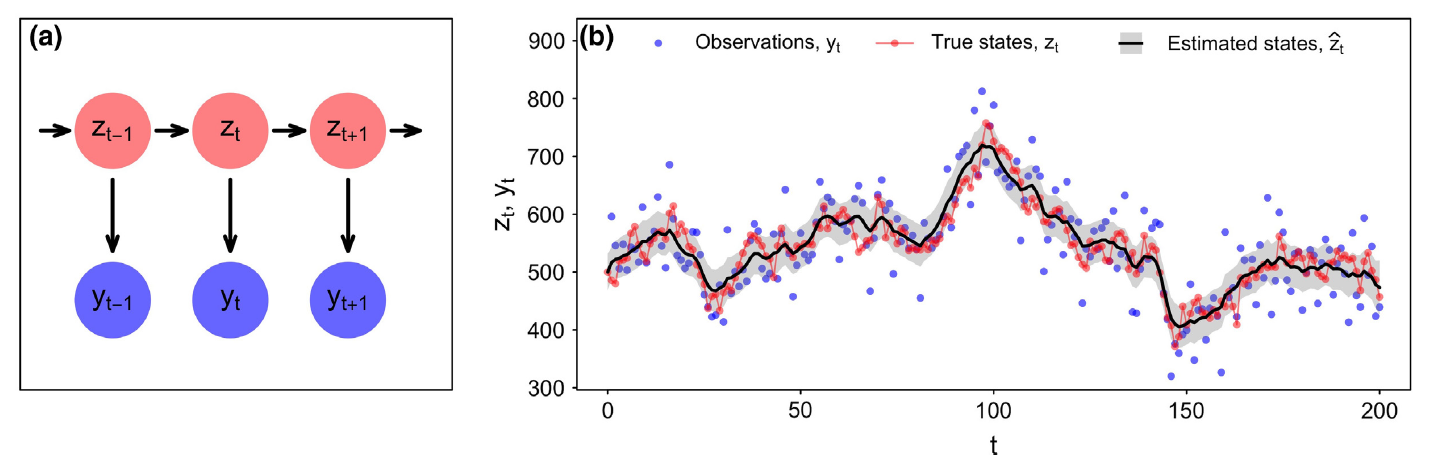
Auger-Méthé et al. (2021)
Referencias

Aeberhard, William H., Joanna Mills Flemming, and Anders Nielsen. 2018. “Review of State-Space Models for Fisheries Science.” Annual Review of Statistics and Its Application 5 (1): 215–35. https://doi.org/10.1146/annurev-statistics-031017-100427.
Auger-Méthé, Marie, Ken Newman, Diana Cole, Fanny Empacher, Rowenna Gryba, Aaron A. King, Vianey Leos-Barajas, et al. 2021. “A Guide to Statespace Modeling of Ecological Time Series.” Ecological Monographs 91 (4). https://doi.org/10.1002/ecm.1470.
Fournier, Daid A, John Hampton, and John R Sibert. 1998. “MULTIFAN-CL: A Length-Based, Age-Structured Model for Fisheries Stock Assessment, with Application to South Pacific Albacore, Thunnus Alalunga.” Canadian Journal of Fisheries and Aquatic Sciences 55 (9): 2105–16.
Fournier, David A., Hans J. Skaug, Johnoel Ancheta, James Ianelli, Arni Magnusson, Mark N. Maunder, Anders Nielsen, and John Sibert. 2012. “AD Model Builder: Using Automatic Differentiation for Statistical Inference of Highly Parameterized Complex Nonlinear Models.” Optimization Methods and Software 27 (2): 233–49. https://doi.org/10.1080/10556788.2011.597854.
Fournier, David, and Chris P. Archibald. 1982. “A General Theory for Analyzing Catch at Age Data.” Canadian Journal of Fisheries and Aquatic Sciences 39 (8): 1195–1207. https://doi.org/10.1139/f82-157.
Gudmundsson, Gudmundur. 1994. “Time Series Analysis of Catch-at-Age Observations.” Applied Statistics 43 (1): 117. https://doi.org/10.2307/2986116.
Haddon, Malcolm. 2011. Modelling and Quantitative Methods in Fisheries. Chapman; Hall/CRC. https://doi.org/10.1201/9781439894170.
Kristensen, Kasper, Anders Nielsen, Casper W. Berg, Hans Skaug, and Bradley M. Bell. 2016. “TMB: Automatic Differentiation and Laplace Approximation.” Journal of Statistical Software 70 (5). https://doi.org/10.18637/jss.v070.i05.
Methot, Richard D., and Chantell R. Wetzel. 2013. “Stock Synthesis: A Biological and Statistical Framework for Fish Stock Assessment and Fishery Management.” Fisheries Research 142 (May): 86–99. https://doi.org/10.1016/j.fishres.2012.10.012.
Nielsen, Anders, and Casper W. Berg. 2014. “Estimation of Time-Varying Selectivity in Stock Assessments Using State-Space Models.” Fisheries Research 158 (October): 96–101. https://doi.org/10.1016/j.fishres.2014.01.014.
Stock, Brian C., and Timothy J. Miller. 2021. “The Woods Hole Assessment Model (WHAM): A General State-Space Assessment Framework That Incorporates Time- and Age-Varying Processes via Random Effects and Links to Environmental Covariates.” Fisheries Research 240 (August): 105967. https://doi.org/10.1016/j.fishres.2021.105967.
Sullivan, Patrick J. 1992. “A Kalman Filter Approach to Catch-at-Length Analysis.” Biometrics 48 (1): 237. https://doi.org/10.2307/2532752.