Modelos avanzados en evaluación de recursos pesqueros: Día 2
Muestreo
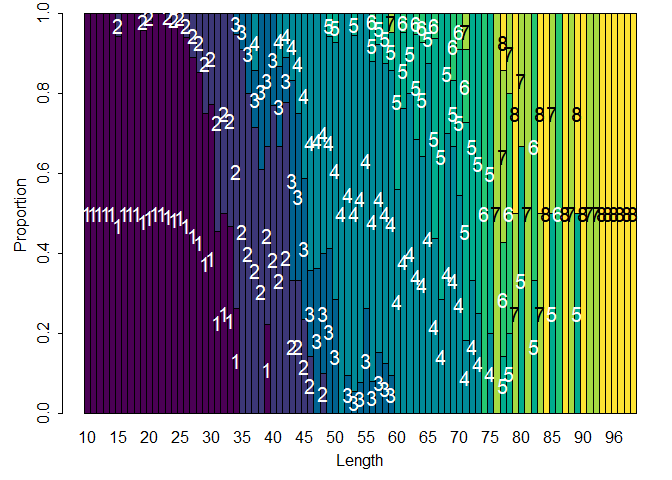
Después de muestrear muchos viajes de pesca o lances en un crucero, se suele construir una clave talla-edad (probabilidad de ser cierta edad dada la talla):
Referencias

Correa, Giancarlo M, Cole C Monnahan, Jane Y Sullivan, James T Thorson, and André E Punt. 2023. “Modelling Time-Varying Growth in State-Space Stock Assessments.” ICES Journal of Marine Science 80 (7): 2036–49. https://doi.org/10.1093/icesjms/fsad133.
Miller, Timothy J., Jonathan A. Hare, and Larry A. Alade. 2016. “A State-Space Approach to Incorporating Environmental Effects on Recruitment in an Age-Structured Assessment Model with an Application to Southern New England Yellowtail Flounder.” Canadian Journal of Fisheries and Aquatic Sciences 73 (8): 1261–70. https://doi.org/10.1139/cjfas-2015-0339.
Miller, Timothy J., and Saang-Yoon Hyun. 2018. “Evaluating Evidence for Alternative Natural Mortality and Process Error Assumptions Using a State-Space, Age-Structured Assessment Model.” Canadian Journal of Fisheries and Aquatic Sciences 75 (5): 691–703. https://doi.org/10.1139/cjfas-2017-0035.
Miller, Timothy J., Loretta O’Brien, and Paula S. Fratantoni. 2018. “Temporal and Environmental Variation in Growth and Maturity and Effects on Management Reference Points of Georges Bank Atlantic Cod.” Canadian Journal of Fisheries and Aquatic Sciences 75 (12): 2159–71. https://doi.org/10.1139/cjfas-2017-0124.
Pedersen, Martin W, and Casper W Berg. 2016. “A Stochastic Surplus Production Model in Continuous Time.” Fish and Fisheries 18 (2): 226–43. https://doi.org/10.1111/faf.12174.
Stock, Brian C., and Timothy J. Miller. 2021. “The Woods Hole Assessment Model (WHAM): A General State-Space Assessment Framework That Incorporates Time- and Age-Varying Processes via Random Effects and Links to Environmental Covariates.” Fisheries Research 240 (August): 105967. https://doi.org/10.1016/j.fishres.2021.105967.
Stock, Brian C., Haikun Xu, Timothy J. Miller, James T. Thorson, and Janet A. Nye. 2021. “Implementing Two-Dimensional Autocorrelation in Either Survival or Natural Mortality Improves a State-Space Assessment Model for Southern New England-Mid Atlantic Yellowtail Flounder.” Fisheries Research 237 (May): 105873. https://doi.org/10.1016/j.fishres.2021.105873.