Modelos avanzados en evaluación de recursos pesqueros: Día 6
Componentes de verosimilitud
Resumen (Francis 2014):
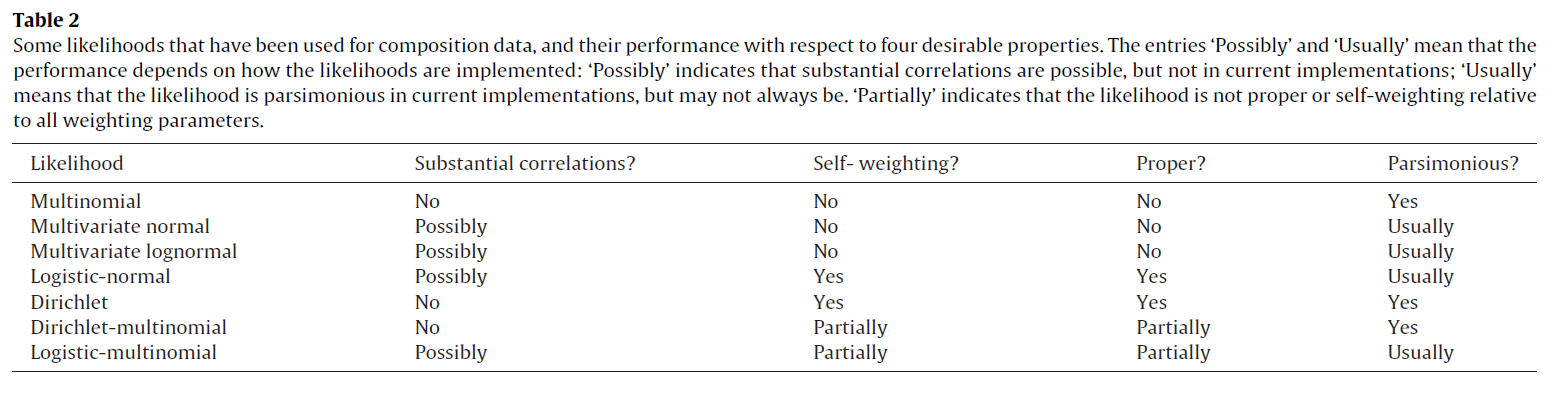
Overview
Objetivo: reducir las discrepancias.
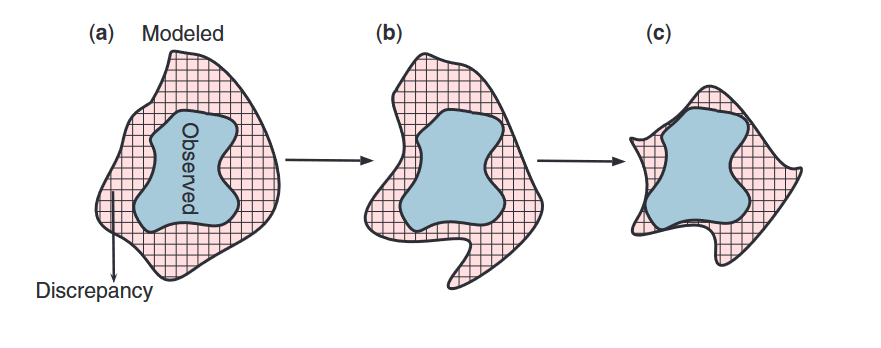
Gradient descent
¿Cómo?: Encontrar el mínimo:
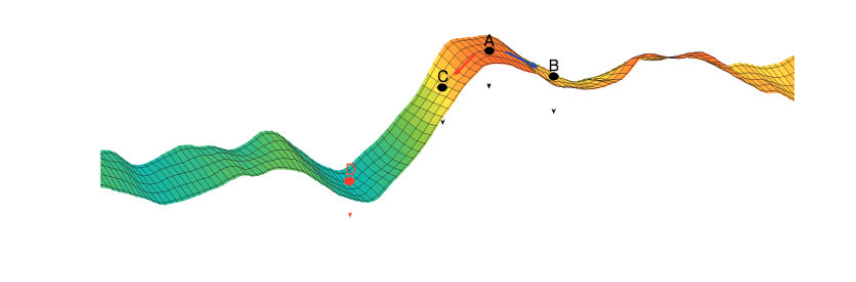
Gradient descent
Pero no es tan sencillo:
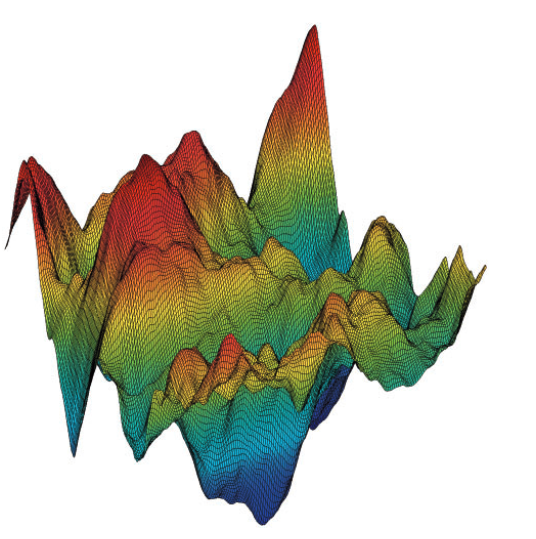
Gradient descent
Superficie depende de varios factores:
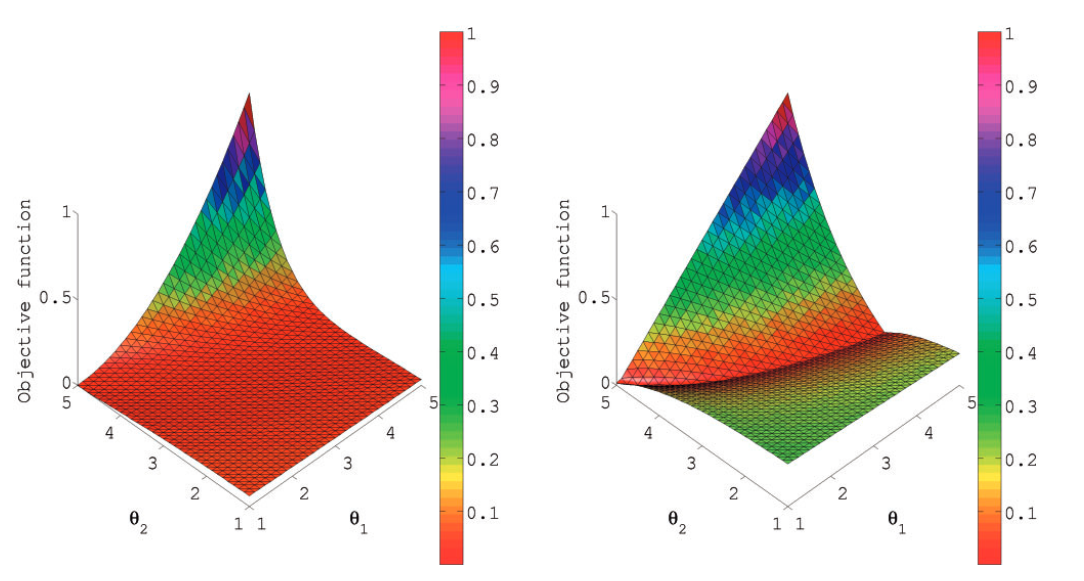
Gradient descent
Mínimo difícil de encontrar por diversos motivos:
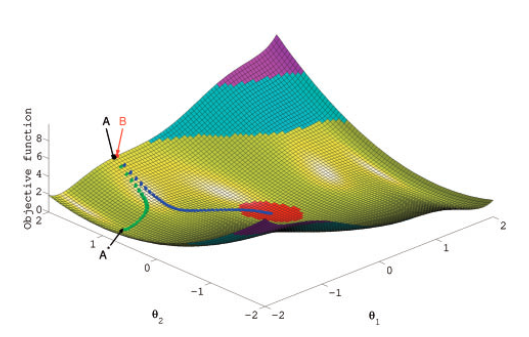
Ejemplo
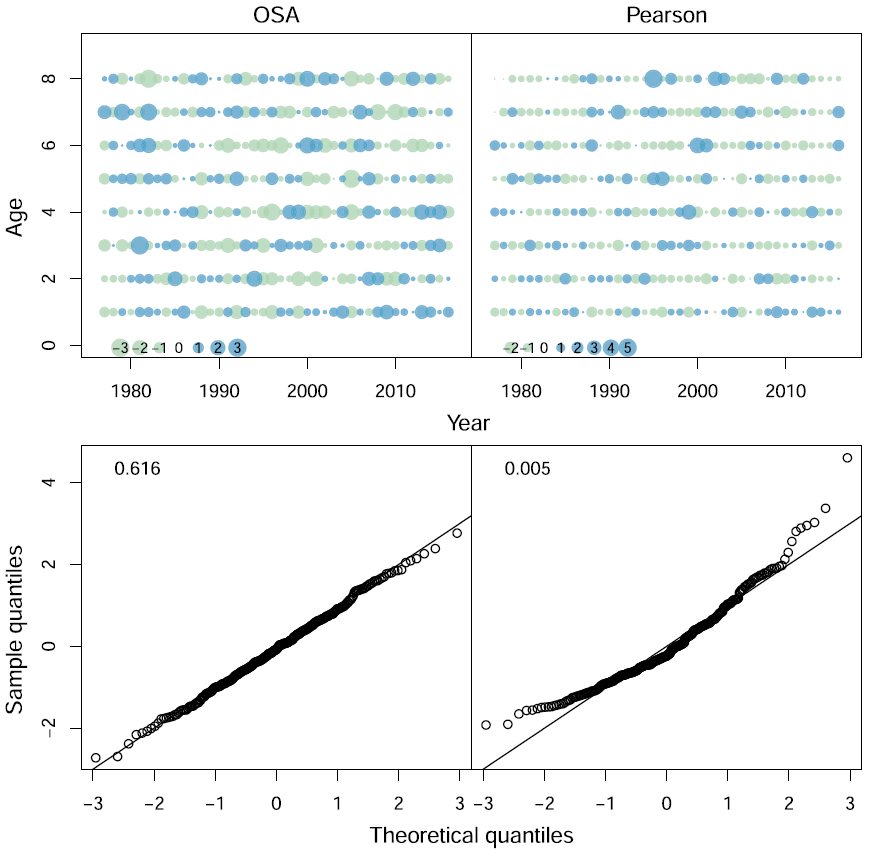
Trijoulet et al. (2023)
Referencias

Aeberhard, William H., Joanna Mills Flemming, and Anders Nielsen. 2018. “Review of State-Space Models for Fisheries Science.” Annual Review of Statistics and Its Application 5 (1): 215–35. https://doi.org/10.1146/annurev-statistics-031017-100427.
Correa, Giancarlo M, Cole C Monnahan, Jane Y Sullivan, James T Thorson, and André E Punt. 2023. “Modelling Time-Varying Growth in State-Space Stock Assessments.” Edited by Pamela Woods. ICES Journal of Marine Science, August. https://doi.org/10.1093/icesjms/fsad133.
Fisch, Nicholas, Ed Camp, Kyle Shertzer, and Robert Ahrens. 2021. “Assessing Likelihoods for Fitting Composition Data Within Stock Assessments, with Emphasis on Different Degrees of Process and Observation Error.” Fisheries Research 243 (November): 106069. https://doi.org/10.1016/j.fishres.2021.106069.
Francis, R. I. C. Chris. 2014. “Replacing the Multinomial in Stock Assessment Models: A First Step.” Fisheries Research 151 (March): 70–84. https://doi.org/10.1016/j.fishres.2013.12.015.
Kristensen, Kasper, Anders Nielsen, Casper W. Berg, Hans Skaug, and Bradley M. Bell. 2016. “TMB: Automatic Differentiation and Laplace Approximation.” Journal of Statistical Software 70 (5). https://doi.org/10.18637/jss.v070.i05.
Ospina, Raydonal, and Silvia L. P. Ferrari. 2012. “A General Class of Zero-or-One Inflated Beta Regression Models.” Computational Statistics &Amp\(\mathsemicolon\) Data Analysis 56 (6): 1609–23. https://doi.org/10.1016/j.csda.2011.10.005.
Subbey, Sam. 2018. “Parameter Estimation in Stock Assessment Modelling: Caveats with Gradient-Based Algorithms.” Edited by Ernesto Jardim. ICES Journal of Marine Science 75 (5): 1553–59. https://doi.org/10.1093/icesjms/fsy044.
Thorson, James T., Kelli F. Johnson, Richard D. Methot, and Ian G. Taylor. 2017. “Model-Based Estimates of Effective Sample Size in Stock Assessment Models Using the Dirichlet-Multinomial Distribution.” Fisheries Research 192 (August): 84–93. https://doi.org/10.1016/j.fishres.2016.06.005.
Thorson, James T, Timothy J Miller, and Brian C Stock. 2022. “The Multivariate-Tweedie: A Self-Weighting Likelihood for Age and Length Composition Data Arising from Hierarchical Sampling Designs.” Edited by Ernesto Jardim. ICES Journal of Marine Science, September. https://doi.org/10.1093/icesjms/fsac159.
Trijoulet, Vanessa, Christoffer Moesgaard Albertsen, Kasper Kristensen, Christopher M. Legault, Timothy J. Miller, and Anders Nielsen. 2023. “Model Validation for Compositional Data in Stock Assessment Models: Calculating Residuals with Correct Properties.” Fisheries Research 257 (January): 106487. https://doi.org/10.1016/j.fishres.2022.106487.